简介
- C++并发编程实战书籍的阅读,学习笔记
第一章 C++的并发世界
- 本章主要内容
- 何谓并发和多线程
- 应用程序为什么要使用并发和多线程
1.1 何谓并发
- 最简单和最基本的并发,是指两个或更多独立的活动同时发生
1.1.1 计算机系统中的并发
计算机领域的并发指的是在单个系统里同时执行多个独立的任务,而非顺序的进行一些活动。
多处理器计算机用于服务器和高性能计算已有多年。基于单芯多核处理器(多核处理器)的台式机,也越来越大众化。无论拥有几个处理器,这些机器都能够真正的并行多个任务。我们称其为硬件并发(hardware concurrency)
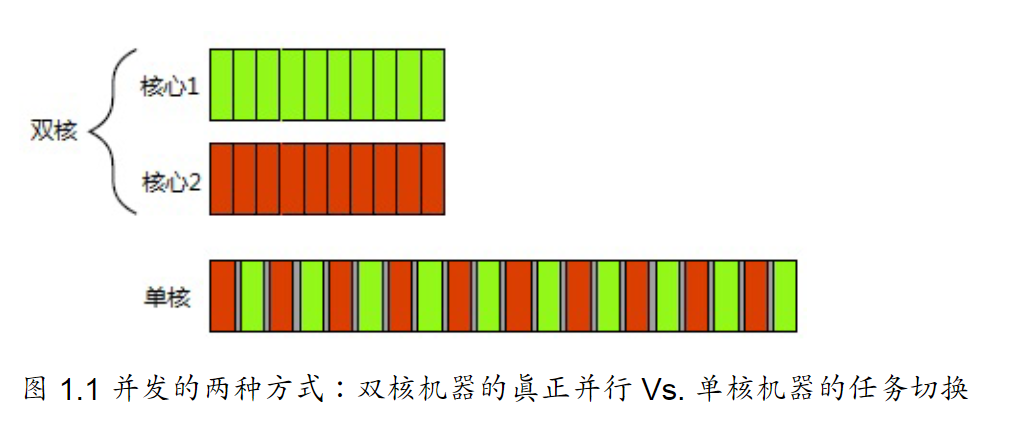
有些处理器可以在一个核心上执行多个线程,但硬件并发在多处理器或多核系统上效果更加显著。硬件线程(hardware threads)最重要的因素是数量,也就是硬件上可以并发运行多少独立的任务。即便是具有真正硬件并发的系统,也很容易拥有比硬件 可并行最大任务数 还要多的任务需要执行,所以任务切换在这些情况下仍然适用。
1.1.2 并发的途径
多进程并发。
使用并发的第一种方法,是将应用程序分为多个独立的进程,它们在同一时刻运行。独立的进程可以通过进程间常规的通信渠道传递讯息(信号,套接字,文件,管道等)。
不过,这种进程之间的通信通常不是设置复杂,就是速度慢,这是因为操作系统会在进程间提供了一定的保护措施,以避免一个进程去修改另一个进程的数据。
多线程并发
并发的另一个途径,在单个进程中运行多个线程。线程很像轻量级的进程:每个线程相互独立运行,且线程可以在不同的指令序列中运行。但是,进程中的所有线程都共享地址空间,并且所有线程访问到大部分数据–全局变量仍然是全局的,指针,对象的引用或数据可以在线程之间传递。
1.2 为什么使用并发
- 主要原因有两个:关注点分离(SOC)和性能。
- 事实上,它们应该是使用并发的唯一原因;如果你观察的足够仔细,所有因素都可以归结到其中一个原因。
1.2.1 为了分离关注点
- 编写软件时,分离关注点是个好主意:通过将相关的代码与无关的代码分离,可以使程序更容易理解和测试,从而减少出错的可能性。
1.2.2 为了性能
- 两种方式利用并发提高性能:
- 第一,将一个单个任务分成几部分,且各自并行运行,从而降低总运行时间。这就是任务并行(task parallelism).
- 区别可能是在过程方面,一个线程执行算法的一部分,而另一个线程执行算法的另一个部分,或是在数据方面,每个线程在不同的数据部分上执行相同的操作(第二种方式)。后一种方法被称为数据并行(data parallelism)
1.2.3 什么时候不使用并发
- 知道何时不使用并发与知道何时使用它一样重要。基本上,不使用并发的唯一原因就是:收益比不上成本。
1.3 C++中的并发和多线程
1.3.4 平台相关的工具
- 虽然C++线程库为多线程和并发处理提供了较全面的工具,但在某些平台上提供额外的工具。为了方便的访问那些工具的同时,又使用标准C++线程库,在C++线程库中提供一个 native_handle() 成员函数,允许通过使用平台相关API直接操作底层实现。
- 就其本质而言,任何使用 native_handle()执行的操作是完全依赖于平台的,这超出了本书,同时也是标准库C++本身的范围。
- 所以,使用平台相关的工具之前,明白标准库能够做什么很重要。
第二章 线程管理
2.1 线程管理的基础
- 每个程序至少有一个线程:执行main()函数的线程,其余线程有其各自的入口函数。线程与原始线程(以main()为入口函数的线程)同时运行。如同main()函数执行完会退出一样,当线程执行完入口函数后,线程也会退出。在为一个线程创建了一个std::thread对象后,需要等待这个线程结束。不过,线程需要先进行启动。
2.1.1 启动线程
- 使用C++线程库启动线程,可以归结为构造 std::thread 对象。
- 有件事需要注意,当把函数对象传入到线程构造函数中时,需要避免最令人头痛的语法解析(C++’s most vexing parse)。如果你传递了一个临时变量,而不是一个命名的变量;C++编译器会将其解析为函数声明,而不是类型对象的定义。
1
std::thread my_thread(background_task());
- 这里相当与声明了一个名为 my_thread 的函数,这个函数带有一个参数(函数指针指向没有参数返回background_task对象的函数),返回一个 std::thread 对象的函数,而非启动了一个线程。
- 使用在前面命令函数对象的方式,或使用多组括号,或使用新统一的初始化语法,可以避免这个问题
1
2std::thread my_thread((background_task())); // 1
std::thread my_thread{background_task()}; // 2 - 使用lambda表达式也能避免这个问题。lambda表达式是C++11的一个新特性,它允许使用一个可以捕获局部变量的局部函数,可以避免传递参数。
- 启动了线程,你需要明确是要等待线程结束(加入式),还是让其自主运行(分离式)。
- 如果不等待线程,就必须保证线程结束之前,可访问的数据得有效性。
2.1.2 等待线程完成
- 在这种情况下,因为原始线程在其生命周期中并没有做什么事,使得一个独立的线程去执行函数变得收益甚微,但在实际编程中,原始线程要么有自己的工作要做,要么会启动多个子线程来做一些有用的工作,并等待这些线程结束。
- join()是简单粗暴的等待线程完成或不等待。当你需要对等待中的线程有更灵活的控制时,比如,看一下某个线程是否结束,或者只等待一段时间(超过时间就判定为超时)。想要做到这些,你需要使用其他机制来完成,比如条件变量和期待(future)。
- 调用join()的行为,还清理了线程相关的存储部分,这样 std::thread 对象将不再与已经完成的线程有任何关联。这意味着,只能对一个线程使用一次join();一旦已经使用过join(),std::thread对象就不能再次加入了。
2.1.4 后台运行线程
- 使用detach()会让线程在后台运行,这就意味着主线程不能与之产生直接交互。也就是说,不会等待这个线程结束;如果线程分离,那么就不可能有 std::thread 对象能引用它,分离线程的确在后台运行,所以分离线程不能被加入。不过C++运行库保证,当线程退出时,相关资源得能够正确回收,后台线程的归属和控制C++运行库都会处理。
- 通常称分离线程为守护线程(daemon threads),UNIX中守护线程是指,没有任何用户接口,并在后台运行的线程。这种线程的特点就是长时间运行;线程的生命周期可能会从某一个应用起始到结束。
2.2 向线程函数传递参数
- 向 std::thread 构造函数中的可调用对象,或函数传递一个参数很简单。需要注意的是,默认参数要拷贝到线程独立内存中,即使参数是引用的形式,也可以在新线程中进行访问。
2.3 转移线程所有权
- C++标准库中有很多资源占有(resource-owning)类型,例如 std::ifstream, std::unique_ptr, std::thread 都是可移动(movable),但不可拷贝(copyable)。这就说明执行线程的所有权可以在 std::thread 示例中移动。
2.4 运行时决定线程数量
- std::thread::hardware_concurrency(),这个函数将返回能同时并发在一个程序中的线程数量。例如,多核系统中,返回值可以是CPU核芯的数量。返回值也仅仅是一个提示,当系统信息无法获取时,函数也会返回 0。
2.5 识别线程
- 线程标识类型是 std::thread::id,可以通过两种方式进行检索。
- 第一种,可以通过调用 std::thread 对象的成员函数 get_id() 来直接获取。如果std::thread对象没有与任何执行线程相关联,get_id()将返回 std::thread::type 默认构造值,这个值表示 没有线程。
- 第二种,当前线程中调用 std::this_thread::get_id()也可以获得线程标识。
- std::thread::id 示例常用作检测线程是否需要进行一些操作,例如:当用线程来分割一项工作,主线程可能要做一些与其他线程不同的工作。这种情况下,启动其他线程前,它可以将自己的线程ID通过 std::this_thread::get_id() 得到,并进行存储。就是算法核心部分(所有线程都一样的),每个线程都要检查一下,其拥有的线程ID是否与初始线程的ID相同。
1
2
3
4
5
6
7
8
9
10std::thread::id master_thread;
void some_score_part_of_algorithm()
{
if (std::this_thread::get_id() == master_thread)
{
do_master_thread_work();
}
do_common_work();
} - 另外,当前线程的 std::thread::id 将存储到一个数据结构中。之后在这个结构体中对当前线程的ID与存储的线程ID做对比,来决定操作是被允许,还是需要。
- 同样,作为线程和本地存储不适配的替代方案,线程ID在容器中可作为键值。例如,容器可以存储其掌控下每个线程的信息,或在多个线程中互传信息。
第三章 线程间共享数据
- 本章主要内容
- 共享数据带来的问题
- 使用互斥量保护数据
- 数据保护的替代方案
3.1 共享数据带来的问题
- 当涉及到共享数据时,问题很可能是因为共享数据修改所导致。如果共享数据是只读的,那么只读操作不会影响到数据,更不会涉及对数据的修改,所以所有线程都会获得同样的数据。。但是,当一个或多个线程要修改共享数据时,就会产生很多麻烦。
- 不变量(invariants)的概念对程序员们编写的程序会有一定的帮助–对于特殊结构体的描述。
- 线程间潜在问题就是修改共享数据,致使不变量遭到破坏。
3.1.1 条件竞争
- C++标准中也定义了数据竞争(data race)这个术语,一种特殊的条件竞争:并发的去修改一个独立对象,数据竞争是未定义行为(undefine behavior)的起因。
- 恶行条件竞争通常发生于完成对多于一个的数据块的修改时。
3.1.2 避免恶性条件竞争
- 这里提供一些方法来解决恶行条件竞争,最简单的办法就是对数据结构采用某种保护机制,确保只有进行修改的线程才能看到不变量被破坏时的中间状态。
- 另一个选择是对数据结构和不变量的设计进行修改,修改完的结构必须能完成一系列不可分割的变化,也就是保证每个不变量保持稳定的状态,这就是所谓的无锁编程(lock-free programming)
- 另一种处理条件竞争的方式是,使用事务(transacting)的方式去处理数据结构的更新(这里的处理就如同对数据库进行更新一样)。所需的一些数据和读取都存储在事务日志中,然后将之前的操作合为一步,再进行提交。当数据结构被另一个线程修改后,或处理已经重启的情况下,提交就会无法进行,这称作为 软件事务内存(software transactional memory, STM)
- 保护共享数据结构的最基本的方式,是使用C++标准库提供的互斥量(mutex)
3.2 使用互斥量保护共享数据
- 当访问共享数据前,使用互斥量将相关数据锁住,再当访问结束后,再将数据解锁。线程库需要保证,当一个线程使用特定互斥量锁住共享数据时,其他的线程想要访问锁住的数据,都必须等到之前那个线程对数据进行解锁后,才能进行访问。这就保证了所有线程能看到共享数据,而不破坏不变量。
3.2.1 C++中使用互斥量
- C++中通过实例化 std::mutex 创建互斥量,通过调用成员函数lock()进行上锁,unlock()进行解锁。不过,不推荐实践中直接去调用成员函数,因为调用成员函数就意味着,必须记住每个函数出口都要去调用unlock(),也包括异常的情况。
- C++标准库为互斥量提供了一个RAII语法的模板类std::lack_guard,其会在构造的时候提供已锁的互斥量,并在析构的时候进行解锁,从而保证了一个已锁的互斥量总是会被正确的解锁。
- 虽然某些情况下,使用全局变量没问题,但在大多数情况下,互斥量通常会与保护的数据放在同一个类中,而不是定义成全局变量。这是面向对象设计的准则:将其放在一个类中,就可让他们联系在一起,也可对类的功能进行封装,并进行数据保护。
3.3 保护共享数据的替代设施
3.3.3 嵌套锁
- 当一个线程已经获取一个 std::mutex 实例时(已经上锁),并对其再次上锁,这个操作就是错误的,并且继续尝试这样做的话,会产生未定义行为。然后,在某些情况下,当一个线程尝试获取同一个互斥量多次,而没有对其他进行一次释放,这样的操作是可行的。这样做的目的是,C++标准库提供了 std::recursive_mutex 类。其功能与std::mutex类似,除了你可以从同一线程的单个实例上获取多个锁。在互斥量锁住其他线程前,你必须释放你拥有的所有锁,所以当你调用lock()三次时,你也必须调用unlock()三次。
- 嵌套所一般用在可被多线程并发访问的类上,所以其拥有一个互斥量保护其成员数据。
第四章 同步并发操作
- 本章主要内容
- 等待事件
- 带有期望的等待一次性事件
- 在限定时间内等待
- 使用同步操作简化代码
- 在上一章中,我们看到各种在线程间保护共享数据的方法。当你不仅想要保护数据,还想对单独的线程进行同步。例如,在第一个线程完成前,可能需要等待另一个线程执行完成。通常情况下,线程会等待一个特定事件的发生,或者等待某一条件达成。这可能需要定期检查 任务完成 标识,或将类似的东西放到共享数据中国,但这与理想情况还是差很多。像这种情况就需要在线程中进行同步,C++标准库提供了一些工具可用于同步操作,形式上表现为条件变量(condition variables)和期望(futures)
4.1 等待一个事件或其他条件
- 当一个线程等待另一个线程完成任务时,它会有很多选择。
- 第一,它可以持续的检查共享数据标志(用于做保护工作的互斥量),直到另一线程完成工作时对这个标志进行重设。
- 第二,在等待线程检查间隙,使用 std::this_thread::sleep_for() 进行周期性的间歇
- 第三,使用C++标准库提供的工具去等待事件的发生。通过另一线程触发等待事件的机制是最基本的唤醒方式,这种机制就称为 条件变量(condition variable)。从概念上来说,一个条件变量会与多个事件或其他条件相关,并且一个或多个线程会等待条件的达成。当某些线程被终止时,为了唤醒等待线程终止的线程将会向等待着的线程广播 条件达成 的信息。
4.1.1 等待条件达成
- C++标准库对条件变量有两套实现: std::condition_variable 和 std::condition_variable_any。这两个实现都包含在
头文件的声明中。两者都需要与一个互斥量一起才能工作(互斥量是为了同步);前者仅限于与 std::mutex 一起工作,而后者可以和任何满足最低标准的互斥量一起工作,从而加上了 _any 的后缀。因为 std::condition_variale_any 更加通用,这就可能从体积,性能,以及系统资源的使用方面产生额外的开销,所以 std::condition_variable_variable 一般作为首选的类型,当对灵活性有硬性要求时,我们才去考虑 std::condition_variable_any。
4.2 使用期望等待一次性事件
- C++标准库模型将这种一次性事件称为 期望(future)。当一个线程需要等待一个特定的一次性事件时,在某种程度上来说它就需要知道这个事件在未来的表现形式。之后,这个线程会周期性(较短的周期)的等待或检查,事件是否触发(检查信息板);在检查期间也会执行其他任务。另外,在等待任务期间它可以先执行另外一些任务,直到对应的任务触发,而后等待期望的状态会变为就绪。

